When using MySQL you may need to ensure the availability or scalability of your MySQL installation. Availability refers to the ability to cope with, and if necessary recover from, failures on the host, including failures of MySQL, the operating system, or the hardware. Scalability refers to the ability to spread the load of your application queries across multiple MySQL servers. As your application and usage increases, you may need to spread the queries for the application across multiple servers to improve response times.
cope with + noun : 극복하다. 잘 처리하다
refer to + noun : 관련되다
spread : 분담하다, 분배하다.
There are a number of solutions available for solving issues of availability and scalability. The two primary solutions supported by MySQL are MySQL Replication and MySQL Cluster. Further options are available using third-party solutions such as DRBD (Distributed Replicated Block Device) and Heartbeat, and more complex scenarios can be solved through a combination of these technologies. These tools work in different ways:
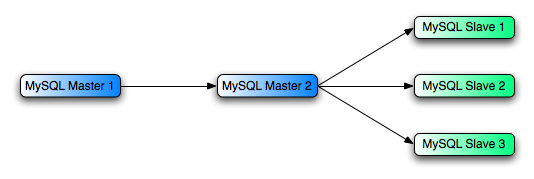
MySQL Replication enables statements and data from one MySQL server instance to be replicated to another MySQL server instance. Without using more complex setups, data can only be replicated from a single master server to any number of slaves. The replication is asynchronous, so the synchronization does not take place in real time, and there is no guarantee that data from the master will have been replicated to the slaves.
Advantages :
- MySQL Replication is available on all platforms supported by MySQL, and since it isn’t operating system-specific it can operate across different platforms.
- Replication is asynchronous and can be stopped and restarted at any time, making it suitable for replicating over slower links, partial links and even across geographical boundaries.
- Data can be replicated from one master to any number of slaves, making replication suitable in environments with heavy reads, but light writes (for example, many web applications), by spreading the load across multiple slaves.
suitable : 적당한, 적절한
partial : 편파적인, 일부분의
boundary : 한계, 경계
sperad : 분배하다. 나누다
Disavantages :
- Data can only be written to the master. In advanced configurations, though, you can set up a multiple-master configuration where the data is replicated around a ring configuration.
- There is no guarantee that data on master and slaves will be consistent at a given point in time. Because replication is asynchronous there may be a small delay between data being written to the master and it being available on the slaves. This can cause problems in applications where a write to the master must be available for a read on the slaves (for example a web application).
consitent : 일관된, 모순이 없는
Recommended uses :
- Scale-out solutions that require a large number of reads but fewer writes (for example, web serving).
- Logging/data analysis of live data. By replicating live data to a slave you can perform queries on the slave without affecting the operation of the master.
Online backup (availability), where you need an active copy of the data available. You need to combine this with other tools, such as custom scripts or Heartbeat. However, because of the asynchronous architecture, the data may be incomplete.
live data : using data 사용중인
affect : ~에 영향을 미치다.
Offline backup. You can use replication to keep a copy of the data. By replicating the data to a slave, you take the slave down and get a reliable snapshot of the data (without MySQL running), then restart MySQL and replication to catch up. The master (and any other slaves) can be kept running during this period.
For information on setting up and confliguring replication, see Chapter 15, Replication.
MySQL Cluster is synchronous solution that enables multiple MySQL instances to share database information. Unlike replication, data in a cluster can be read from or written to any node within the cluster, and information will be distributed to the other nodes.
Advantages :
- Offers multiple read and write nodes for data storage.
- Provides automatic failover between nodes. Only transaction information for the active node being used is lost in the event of a failure.
- Data on nodes is instantaneously distributed to the other data nodes.
instantaneously : 즉시
Disadvantages :
- Available on a limited range of platforms.
- Nodes whithin a cluster should be connected via a LAN; geographically separate nodes are not supported .However, you can replicate from one cluster to another using MySQL Replication, although the replication in this case is still asynchronous.
Recommended uses :
- Applications that need very high availability, such as telecoms and banking.
- Applications that require an equal or higher number of writes compared to reads.
For information on MySQL Cluster, see Chapter 16, MySQL Cluster.
DRBD(Distributed Replicated Block Device) is a solution from Linbit supported only on Linux. DRBD creates a virtual block device(which is associated with an underlying physical block device)that can be replicated from the primary server to a secondary server. You create a filesystem on the virtual block device, and this information is then replicated, at the block level, to the secondary server.
underlying : 기본적인, 근원적인, 기초를 이루는
Because the block device, not the data you are storing on it, is being replicated the validity of the information is more reliable than with data-only replication solutions. DRBD can also ensure data integrity by only returning from a write operation on the primary server when the data has been written to the underlying physical block device on both the primary and secondary servers.
validity : 타당성, 유효성
reliable : 신뢰하다, 신용하다
ensure : 확실하게 하다. 보장하다
integrity : 고결, 완전한 (상태)
Advantages :
- Provides high availability and data integrity across two servers in the event of hardware or system failure.
- Ensures data integrity by enforcing write consistency on the primary and secondary nodes.
consistency : 일관성
Disadvantages :
- Only provides a method for duplication data across the nodes,. Secondary nodes cannot use the DRBD device while data is being replicated, and so the MySQL on the secondary node cannot be simultaneously active.
- Cannot provide scalability, since secondary nodes don’t have access to the secondary data.
simultaneously : 동시에
Recommended uses :
- High availability situations where concurrent access to the data is not required, but instant access to the active data in the event of a system or hardware failure is required.
For information on configuring DRBD and configuring MySQL for use with a DRBD device, see Section 14.1. “Using MySQL with DRBD for High Availability”
Heartbeat is a software solution for Linux. It is not a data replication or synchronization solution, but a solution for monitoring servers and switching active MySQL servers automatically in the event of failure. Heartbeat needs to be combined with MySQL Replication or DRBD to provide automatic failover.
The information and suitability of the various technologies and different scenarios is summarized in the table below.
suitability : 적당한
various : 다양한, 여러가지, 색색
MySQL을 사용한다면, MySQL 설치에 가용성 또는 확장성을 고려할 필요가 있습니다. 가용성은 MySQL, OS, H/W down을 포함한 host server의 down으로 부터의 복구하거나, 잘 처리하는 능력과 관련됩니다.
확 장성은 다수의 MySQL servers로 application queries의 load를 분담하는 능력과 관련됩니다. Application이나 사용량이 증가하면, response times의 개선을 위해 다수의 servers로 application queries를 분담할 필요가 있습니다.
아래는 가용성과 확장성의 issues를 해결 가능하는 solutions입니다. 두 개의 solutions은 MySQL의 Replication과 Cluster로 제공됩니다. Further : 더 나아가서, 그 이상의 options은 third-party solutions을 통한 DRBD (Distributed Replicatted Block Device)와 Hearbeat, 그 기술들을 혼합시켜 만든 더 복잡한 시나리오로 처리 가능합니다. 이들 기능은 각기 다른 방법으로 일을 합니다.
MySQL Replication 가능한 상황들과 하나의 MySQL server instance로부터의 data는 다른 MySQL server instance로 Replicate 될 수 있다. 복잡한 설정 없이, 단지 data는 단일 master server에서 다른 많은 slaves로 replicate 할 수 있다. Replication은 비동기로, 그래서 실시간으로 동기화 하지 않고, 제약없이 master로 부터 slaves로 data를 replicate 할 것이다.
Advantages :
- MySQL Replication은 MySQL이 지원되는 모든 platforms에서 사용가능하고, 시스템 특성에 따라 작동하고 있지 않은 관계로, 다른 platforms 사이에서도 동작 가능하다.
- Replication은 비동기로 언제라도 stop 및 restart 가능하고, 느린 링크들, 편파적인 링크들, 위치적인 한계를 뛰어 넘어 replicating을 하기 적절하게 하고 있다.
- Data 는 하나의 master로부터 많은 수의 slaves로 replicate 할 수 있고, 다중의 slaves사이의 부하를 분배하기 위해 많은 reads, 적은 writes (예를 들면, 많은 web applications)의 환경에 적절하다.
Disavantages :
- Data는 단지 master에만 쓸 수 있다. 보다 발전된 환경에선 data는 링의 형태의 replcate되고 다중의 master 환경을 설정 할 수 있다.
- 제 약없이 master와 slaves에게 주어진 시간에 일관되게 data를 보낼 것이다. Replication은 data가 master에 쓰여지게 될 때, slaves에 그것이 가능하도록 작은 지연이 발생하는 비동기 방식이기 때문이다.이것은 master에 쓰고, slaves에서 읽어야만 하는 예를 들면 web application같은 app에서 문제를 야기 시킬 수 있다.
Recommended uses :
- Scale-out solutions으로 많은 수의 reads 이나 적은 writes인 예를 들면 web serving.
- 사용중인 data의 Logging/data analysis. 사용중인 data를 slave로의 replicate 하는 것에 의해 master의 동작환경에 영향을 끼치는 것 없이 queries을 개선 가능하다.
- Online backup (가용성), 살아 있는 가용 data의 copy가 필요할 때. 이것들을 준비된 스크립트 또는 Heartbeat 와 같은 다른 tools과 함께 조합 할 필요가 있다.
Offline backup. data를 복사하면서 replication을 사용 할 수 있다. slave로 data를 replcation 하는 것으로 slave를 정지시키거나, Mysql를 가동하지 않고도 data의 snapshot을 얻을 수 있고, MySQL을 재기동 하면, replication이 활성화 된다. Master(또, 어떤 다른 slaves)는 이 기간 동안 계속 가동 가능하다.
replication의 set up 및 설정에 대한 정보는 Chapter 15, Replication을 참조하세요.
MySQL Cluster은 database information 공유로 다중의 Multiple MySQL instances 가능한 동기 solution이다. replication과 다르게, cluster에서 data는 cluster에 포함된 어떤 node에서도 read/write가 가능하고, Information은 다른 nodes로 분산 되게 됩니다.
Advantages :
- data storage를 통해 multiple read/write nodes 제공합니다.
- Nodes 사이의 자동 failover를 제공. 단 활성 node가 사용하고 있는 transaction information은 failure event로서 손실 됩니다.
- Nodes 상의 data는 즉시 다른 data nodes로 분할 됩니다.
Disadvantages :
- 사용가능한 platforms이 제한 되어 있습니다.
- cluster에 포함된 Nodes는 via a LAN으로 접속 해야 합니다; 물리적으로 분리된 nodes는 지원하지 않습니다. 그리고, 하나의 cluster에서 다른 MySQL Replication으로 replcation 가능합니다, 하지만 이 경우의 replcation은 비동기가 됩니다.
Recommended uses :
- 통신이나 은행과 같은 매우 높은 가용성을 필요로하는 Applications.
reads와 writes가 동일하거나 writes가 많은 비중을 차지하는 Applications.
MySQL Cluster의 정보는 Chapter 16, MySQL Cluster를 참조하세요.
- DRBD는 Linux 상의 단지 Linbit(?)으로부터 지원되는 solution이다. DRBD는 primary server로부터 secondary server로 replicate 가능한 virtual block device(기본적인 physical block device로 연관되어진)를 생성한다.
- Virtual block device 상에서 filesystem를 만들고, 이 information은 secondary server로 block level로 replicate 된다.
보 관하고 있는 data가 아닌, 그 정보의 유효성을 replicate하고 있는 block device이기 때문에, data만 replication하는 solutions보다 더 신뢰가능하다. DRBD는 또한 primary와 secondary servers 양쪽의 본래의 physical block device로 쓰여질 때, primary server의 write operation으로 부터 return되므로 data의 완전성(고결성)을 보장한다.
Advantages :
- 두 servers 사이의 hardware의 event 혹은 system failure에서 높은 가용성과 data의 고결성을 제공한다.
Disadvantages :
- 단 지 nodes 사이에서 data를 복제하기 위한 방법을 제공한다. Secondary nodes는 data를 replicate하고 있는 동안에는 DRBD device를 사용할 수 없고, secondary node상의 MySQL은 동시에 활성화 될 수 없다.
Recommended uses :
- data로의 concurrent access 고 가용성 상황에는 적합하지 않지만, system의 evnet 혹은 hardware failure에서 활성 data로의 즉각적인 aceess에는 적합하다.
DRBD 설정과 DRDB device를 사용하기 위한 MySQL 설정 정보는 Section 14.1 “Using MySQL with DRBD for High Availability”를 참조하세요.
Heartbeat 는 Linux를 위한 software solution 입니다. data replication 또는 synchronization solution이 아니라, failure event를 자동으로 active 상태의 MySQL servers를 switching하고 servers를 monitoring하는 solution입니다. Heartbeat는 MySQL Replication 혹은 자동 failover를 제공하는 DRBD와 조합이 필요합니다.