
Net Journalist 佐?木씨가 차세대 Social Media의 형태를 심층분석한 연재 “Social Media Second Stage”. 제 3회에서는 Contents Filtering, Collaborative Filtering에서는 얻을 수 없는 “고객속성”에 근접한 “Behavieral Marketing”에 대해서 이야기 합니다.
(2007년 9월 25일 자료)
“고객의 속성”을 읽어내는 방법
연재의 지난회에서 Collaborative Filtering에서는 고객 간의 행동의 유의성을 보고 있는 것일 뿐, “고객의 속성을 보고 있지 않다”라는 문제가 있다고 했었다. 예로, 부인에게 선물을 하기위해 남편이 여성용 화장품을 구입하면, 그 후 얼마동안은 여성용 화장품에 관한 추천들이 끊이질 않는 현상이 일어나 버리는 것과 같은 것이었다. 그리고, 이런 고객의 속성을 보고 있지 않다라는 문제는 Contents Filtering에서도 Collaborative Filtering에서도 Cover 할 수 없는 것이라고도 적었었다.
「물건을 산다」라는 행동을 분석해 보자. 나눠서 분석하면, 다음과 같은 3가지로 나눌 수 있다.
- 상품의 속성 (그 상품이 어떤 분야의 상품으로, 어떤 이름을 가지고, 어떤 특성이 있는것인가?)
- 고객의 속성 (고객의 성별, 주거지, 나이, 좋아하는 것등)
- 상품과 고객의 연결 이력들 (어떤 고객이 어떤 상품을 과거에 구입했었나라는 이력)
이 중 최초의 「상품의 속성」을 잘 활용 할 수 있는 기술은 Contents Base의 Filtering (Contents Filtering). 마지막의 「상품과 고객의 연결 이력」을 분석가능한 것은 Collaborative Filtering이다. 그리고, 두번째의 「고객의 속성」에 대해서는 어떤 기술이 사용되고 있냐하면, Recommendation 분야에서는 앞서서 해석하는 것은 아직 그다지 나타나고 있지 않다. 그러나, Recommendation 이외의 분야로 눈을 돌리면, Behavieral Targeting라는 것이 있다.
※ Behavieral Targeting이란?
Internet User (엄밀하게는 Browser Cookie)의 여러가지 행동을 해석, 분석해서, Targeting할 대상 User를 선별하는 것이다. Internet User의 여러 행동에는 소비행동을 도달점으로하여, 그곳에 다다르기까지 여러가지의 단계가 있다. 단계에 따라서, User의 심리상태나 행동 Pattern은 다르고, 또 User 개개인을 비교해 보면, 더욱더 상세하게 다른 걸 알 수 있다.
User의 다양화가 가속화 하는 상황에서 Marketing의 효율화를 요구하는 Internet Marketing활동에 있어서 User 개개인의 행동 Pattern을 해석, 분석한 후에 적절한 Approach를 하는 Behavieral Targeting, 혹은 Behavieral Targeting Service는 빼놓을 수 없는 존재가 되고 있다.
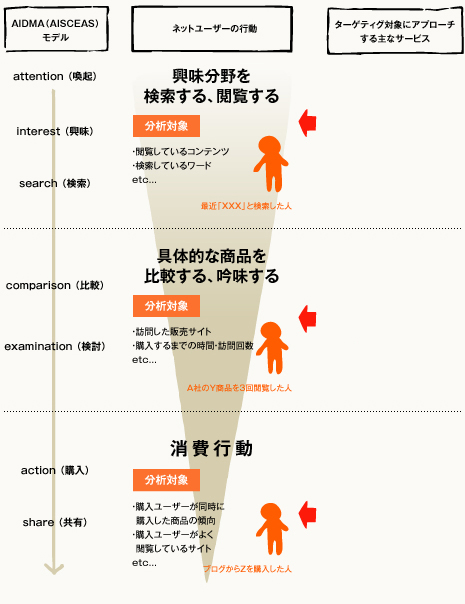
Behavieral Targeting광고는 2006년 쯤부터 일본의 Internet광고 업계에서도 급격히 증가하고 있다. 고객이 어떤 Web Site를 보거나, 어떤 Keyword로 검색을 했는가라는 이력을 전부 축적하여, 그 내용에 맞춰 고객의 흥미나 관심이 있을 만한 광고를 보여주는 것이다.
예를들면, Swimming가 취미로, 그래도 평일은 Business Person으로서 바쁘게 일하고 있는 여성, A를 생각해 보자. Amazon은 Recommendation에 Behavieral Targeting은 채용하고 있즈 않기 때문에, A가 과거에 Business 책을 계속 구입하고 있었다라고 하면, 당연하게 다른 Business 책을 추천한다. 상품과 고객의 연결 이력을 보는 Collaborative Filtering나, 상품과 상품의 유의성에 주목하는 Contents Filtering에서는 A에게 Swimming 관련의 책이나 Swim Suit를 추천할 이유는 어디에도 없다. 처음부터 Amazon.co.jp상의 이력에는 Swimming 관계의 구매이력은 아무것도 기록되어 있지 않기 때문이다.
그래도, 어쩌면 A는 이 날은 휴일로, 언제나 처럼 Office가 아닌, 집에서 Amazon.co.jp에 Access했을 지도 모른다. 그런 것들은 Site에서 인식하는 것은 거의 무리에 가깝지만(IP Address로부터 추척하여… 같은 Privacy에 저촉되는 일을 하지 않는 한), 그러나 오늘이 특별한 날이라는 것을 인식하는 방법이 한개 있다. Behavieral Targeting이다.
Behavieral Targeting의 구조와 Adware의 실패
예로, A는 Amazon Site를 방문하기 전에, 다른 Site에서 Swim Suit를 구입하고, 더불어 그 전에는 Search Engine에서 「세계수영」을 검색하고, 멜버른에서 봄에 열렸던 세계 수영 선수권의 정보를 읽었다고 한다. 만약 이 행동이력을 Amazon이 알고 있다면, 「항상 A는 Business 책을 사지만, 오늘은 왠지 다르네. 수영 Site를 읽고, 그 후 수영 Goods를 구입한 후 Amazon.co.jp에 방문했어. 그럼, 수영 관련 서적이나 Swimming Goods를 Recommendation해보자」라고 판단하고, 수영 관련 상품을 추천하는게 가능할 것이다.
이 Behavieral Targeting은 고객이 어떤 행동을 해 왔는가라는 이력을 기반으로, 고객의 속성을 취득하는 셈이다. 그렇지만, 고객의 속성이라는 것은 고객의 과거의 이력 뿐만이 아니라, 고객이 지금 어떤 취미를 가지고 있고, 년수입은 얼마이고, 무엇을 사려고 하고 있는 지등의 Direct한 정보도 필요할 것이 틀림없다. 그러나, 이런 Direct한 정보는 Privacy 준수의 요구가 상당히 높은 지금, 손에 넣기 상당히 힘들게 되어 있다. 「개인정보를 더욱더 입력해 주세요! 그것에 맞춰 상품을 추천하겠습니다!」라는 Site가 따뜻하게 불러 모아도, 소비자 입장에서는 「무슨 바보같은 소리. 내가 속을까봐」라고 역으로 받아들여 버린다.
그래서 Behavieral Targeting와 같은 비교적 이런 걸 피해가는 방법이 이용되어지게 되었다. 그렇지만, 역시 Privacy 관점으로부터 Behavieral Targeting가 많은 비판을 받았던 적이 있다. 더욱 유명한 것은 1990년대 말의 「Adware」비판이다. Adware라고 불리던 Program은 Web Browser를 통하여 몰래 이용자의 PC에 Install된다. 그리고, 이용자의 행동을 감시, 맘대로 광고를 이용자의 PC에 표시하거나, 이용자의 개인정보를 일어내는 등의 일을 했다. 예로, 당시 Adware 최대 업체였던 미국의 Cydoor사는 Web Browser 「Opera」나 번역 Soft 「Babylon」등의 많은 인기 Soft에 동봉되어 이들 Soft를 Install하면 동시에 Adware도 Install되도록 하는 구조를 만들어 내었다. 그리고, 일단 Install되면 대량의 광고를 PC의 화면에 표시하게 하는 행위를 했다.
그러나, 이런 Adware의 상당수는 그 후 이용자에게 미움을 받는 결과가 되어, Computer Virus와 같은 취급을 받게 되어 없어졌다. 이러한 광고수법도 사라졌다. 그 후 2000년에는 Net 광고 핵심 기업인 미국의 DoubleClick가 Behavieral Targeting을 실시하려고, 미연방공정거래위원회(FTC)로부터 조사를 받는 사건도 있었다. DoubleClick은 Database의 핵심 기업을 매수하고, 이 회사가 가지고 있던 고객의 Database와 자가가 가지고 있던 Net 이용자의 행동이력을 연계시켜, 적절한 광고를 보내려고 생각했던 것이다. 그러나, 이 계획에는 Privacy 보호의 소비자단체인 EPIC(Electronic Privacy Information Center)가 「알지도 못하는 사이에 맘대로 Data를 수집한 점이 근본적으로 이상하고, 정보수집이 발생하기 전에 이용자의 허가를 얻지 않았다.」라고 지적하여, FTC에 조사를 요청하여 회사문제가 되었던 것이다.
고객에게 미움받지않고 고객속성을 취득
이 같은 과거의 아픈 경험이 있었기 때문에, 고객의 속성을 취득하고자 하는 Business는 정체되었다. Recommendation 분야에서도 이 부분이 그다지 발전되지 못했던 것은 아마도 이런 과거의 경위가 꼬리를 잡고 있었던 것은 아닌가 생각되어 진다. 지금에 와서, 고객의 속성을 일어내는 Recommendation으로서 Service화 되어 있는 것은 지난 회에서의 6개의 Recommendation 분류로 말하면, 1)의 「Rule에 기반한 Recommendation」뿐이다. 이것은 「Printer를 샀던 사람에게, Ink Toner를 추천한다」「멜로영화를 좋하하는 사람에게 신작의 멜로영화를 추천한다」등, 어떤 제품을 샀던 사람이나 처음에 자신이 좋아하는 것을 등록하고 있는 사람에 대해서, 특정의 상품이나 Service를 추천한다라고 하는 Rule을 정해두는 방법이다. 그렇지만, 이 방법으로는 고객이 자신의 속성 (예로, 「Techno POP이 좋다」「소설이라면 村上春樹(무라카미 하루키)가 좋다」「피부는 이야기하자면 건성 피부」「년수입은 6,000만원」등의 정보)를 등록해 두지 않으면 안되기 때문에 고객에게 미움을 받는다.
이렇게 되면 기업 측은 역시「고객이 스스로 자각없이, 자신의 정보를 제공해 준다. 그 속성정보를 기반으로, 무언가 추천하고 싶다.」라는 방법을 요구하게 된다. 그러나, 이것은 좀 전에도 Adware를 예로 썼던 것과 같이, Privacy 침해가 되어버릴 가능성이 크다. Privacy와 고객속성이라는 것은 Trade Off가 되기 싶기 때문이다.
여기에 Behavieral Targeting의 등장이다. 2002년 이후에 처음은 미국에서 점점 확대된 새로운 Behavieral Targeting광고는 개인정보에는 일절 손을 대지않는다라는 것을 명확하게 하고 있기 때문에 Cookie만을 사용한 수법이 확립되어 있다. Cookie라면, 이용자의 PC에 「이 이용자가 언제 우리 Site를 방문했는가」「몇번 방문했는가」「어느 페이지를 읽었는가」라는 정보를 보존할 수 있다. 이용자가 자사 Site에서 어떤 행동을 하고 있는지는 포착할 수 있지만, 그러나 이용자의 개인정보를 훔치는 것은 하지 않는다. 단지 Web Site측이 정보를 이용자 PC에 보존하는 것 뿐으로 이용자의 PC로부터 타 정보를 읽어내는 것은 아니기 때문이다. Cookie만으로 개인을 특정하는 것은 기본적으로 불가능하다.
이런 Cookie의 특성은 Privacy 관점으로부터 보았을 때 Behavieral Targeting의 Data로서 바람직하다고 생각되어 지게 되었다.
규모를 활용시키는 Yahoo가 Leader로
일본에서는 Behavieral Targeting의 도입은 더욱이 늦어져 2006년 쯤 시작되었다. 역시 배경에는 2003년 개인정보보호법시행이었다. 이 법률에 불안을 느낀 많은 기업이 Privacy 침해에 저촉될 수 밖에 없는 Behavieral Targeting광고를 도입하는 것을 피했기때문이 아닌가라고 생각되어진다. 하지만, 고객정보누수사건이 그다지 이야기거리가 되지 않게 되고, Privacy에 관한 사회적 관심도가 안정되자, Behavieral Targeting은 한꺼번에 Net 광고업계에 유입되기 시작했다. 그 앞단에 선 것이 Yahoo이다. Yahoo는 2006년 1월부터 시험적으로 실시를 개시하여, 같은 해 7월부터 본격도입을 개시, 이 분야에 있어 Leader 기업이 되었다.
그렇지만, 이 Behavieral Targeting Model이 Recommendation의 일반적인 수법으로서 더욱 보급될지 어떨지를 말하자면, 그렇지도 않다. 왜냐면, Behavieral Targeting에서는 현재의 Site를 방문하기 전에 고객이 어떤 Site를 방문했었는가라는 Data를 취득 할 수 없기 때문이다. Yahoo와 같은 100이상의 Contents를 가진 거대 Potal Site라면, 자사 Potal 내부만으로 고객의 행동이력을 파악하는 것이 가능하게 되어, 효과적으로 Behavieral Targeting을 행할 수 있다. 그래서, Yahoo가 Behavieral Targeting광고를 향해 갔던 것은 말하자면 「규모의 필연」과 같은 것이었다.
이것이 Potal이 아닌, 하나의 Site가 되면 다른 Site와 Behavieral Targeting으로 연계가 필요하게 된다. 예로, NEC Biglobe와 Niffty, Atnethome은 2007년 5월, Behavieral Targeting광고를 공동으로 전개하기로 합의했다고 발표했다. 3사의 공동 전개의 형태로 역시 규모의 Merit를 노린 것이었기때문이다. 하나의 회사만으로는 Net 이용자의 수가 적고, Behavieral Targeting의 효과를 충분히 낼 수 없지만, 3개의 회사가 합쳐지면 월간 이용자수는 2700만명에 다다르게 되고, Site내에서의 이동도 포함하여 규모의 Merit를 충분하게 살릴 수 있는 셈이다.
이 Behavieral Targeting Model은 이후, Recommendation 세계를 크게 변화시킬 수 있는 가능성을 품고 있다. 그렇지만, 여기까지 써왔던 것과 같이 Behavieral Targeting와 같은 고객속성을 취득하는 Model로는 Privacy 문제등 여러가지 장벽이 막고 있는 것이 현실이고, 그렇게 간단하게 앞으로 나아가지 못한다.
그래서, 최근 주목되기 시작한 것은, 통계학적인 Approach이다. 다음회에 이것에 대해서 생각 해 보자.
※ 위 글은 아래의 링크를 번역한 글입니다. 다소 오역이 있을 수 있습니다.
http://www.itmedia.co.jp/anchordesk/articles/0709/25/news077_2.html
