
As the number of slaves connecting to a master increases, the load, although minimal, also increases, as each slave uses up a client connection to the master. Also, as each slave must receive a full copy of the master binary log, the network load on the master may also increase
and start to create a bottleneck.
If you are using a large number of slaves connected to one master, and that master is also busy processing requests (for example, as part of a scaleout solution), then you may want to improve the performance of the replication process.
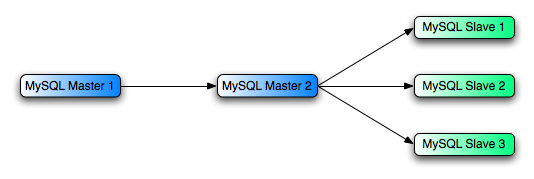
One way to improve the performance of the replication process is to create a deeper replication structure that enables the master to replicate to only one slave, and for the remaining slaves to connect to this primary slave for their individual replication requirements. A sample of this
structure is shown in Figure 14.3, “Using an additional replication host to improve performance”.
For this to work, you must configure the MySQL instances as follows:
- Master 1 is the primary master where all changes and updates are written to the database. Binary logging should be enabled on this machine.
- Master 2 is the slave to the Master 1 that provides the replication functionality to the remainder of the slaves in the replication structure. Master 2 is the only machine allowed to connect to Master 1. Master 2 also has binary logging enabled, and the –log-slave-updates option so that replication instructions from Master 1 are also written to Master 2’s binary log so that they can then be replicated to the true slaves.
- Slave 1, Slave 2, and Slave 3 act as slaves to Master 2, and replicate the information from Master 2, which is really the data logged on Master 1.
The above solution reduces the client load and the network interface load on the primary master, which should improve the overall performance of the primary master when used as a direct database solution.
If your slaves are having trouble keeping up with the replication process on the master then there are a number of options available:
- If possible, you should put the relay logs and the data files on different physical drives. To do this, use the –relay-log option to specify the location of the relay log.
- If the slaves are significantly slower than the master, then you may want to divide up the responsibility for replicating different databases to different slaves. See Section 14.2.4, “Replicating Different Databases to Different Slaves”.
- If your master makes use of transactions and you are not concerned about transaction support on your slaves, then use MyISAM or another non-transactional engine. See Section 14.2.2, “Using Replication with Different Master and Slave Storage Engines”.
- If your slaves are not acting as masters, and you have a potential solution in place to ensure that you can bring up a master in the event of failure, then you can switch off –log-slave-updates. This prevents ‘dumb’ slaves from also logging events they have executed into their own binary log.
Master에 접속하고 있는 slaves 수가 증가하면, 약간의 부하도 어느정도 증가하여, 각각의 slave가 master로의 client connection을 전부 써 버립니다. 게다가, 각각의 slave는 master의 binary log의 완전한 copy를 받을 필요가 있기 때문에, master network load도 같이 증가하여, bottleneck이 발생 system 전체 성능이 저하합니다.
Scale-out solution등으로 master에 접속하고 있는 slave 수가 많을 때는, 그것에 맞춰 master의 처리량을 증대 시키기 때문에, Replication process의 performance를 개선할 것을 추천합니다.
Replication process의 performance를 개선하는 방법의 하나로, 보다 깊은 Replication structure를 구성하는 것이 있습니다. 이것은 master가 1개의 slave만 복제를 행하고, 다른 slave는 개별 replication 요구로 대응하는 primary slave에 접속하는 방법입니다. 이 structure sample는 그림, 5.8 “추가 Replication host로 performance 개선”을 참조 해 주세요.
이것을 실현하기 위해, MySQL instances를 다음과 같이 설정합니다.
- Master 1은 primary master로 이 database에 모든 change와 update가 write됩니다. Binary logging은 이 machine에서 실행가능합니다.
- Master 2는 Master1의 slave입니다. Master 1은 replication structure에 있어, Replication의 기능성을 slave의 잔여분으로 제공합니다. 여기서 Master 2는 Master 1에 단일 접속하는 machine입니다. Master 2는 binary logging가 가능한 상태입니다. –log-slave-updates option으로 Master 1으로부터 복제지시가 Master 2의 binary log에 write되고, 이것에 의해, 양자가 slave 복제하게 됩니다.
- Slave 1, Slave 2, Slave 3는 Master 2의 slave로써 가동되고, Master 2로부터 정보를 복제하지만, 실제는 Master 1의 log data입니다.
이 solution은 primary master의 client load뿐만이 아니라, Network interface load를 줄이는게 가능하고, primary master의 performance 전체를 개선하는 direct database solution으로 활용가능합니다.
Master의 replication process에 있어 문제를 일으키는 slave가 있는 경우에는 다음 option으로 대응합니다.
- Relay log와 data files을 가능한 한 물리적으로 독립된 drive에 분리합니다. 그렇게 하기위해, –relay-log option을 사용하여, relay log의 보관장소를 지정합니다.
- Slave가 master보다 매우 느린 경우는, database 종류에 맞춰 복제 역활을 다른 slave에 나눠주는 것을 추천합니다. 자세한 내용은 5.3.4. “다른 database로부터 다른 slave로의 replication”을 참조 하세요.
- Master transaction을 활용하고, slave가 그 transaction support를 하고 있는 지 어떤지를 확인하기 위해, MyISAM 또는 그 외의 non-transaction engine을 사용합니다. 자세한 내용은 5.3.2 “Storage engine가 다른 master와 slave의 replication”을 참조 하세요
Slaves가 masters처럼 가동하고 있지 않는 상황에서, 대처가능한 방법이 있고, 장애 event 중의 master를 조작 할 수 있는 경우에는, –log-slave-updates option을 사용합니다. 이것은 “dumb(처리능력없음)” slave가 또, 각각의 binary log에 실행했던 event를 기록하는 것을 방지합니다.

I rread this paragraph completely concerning the resemblance of hottest andd previous technologies, it’s awesome article.